ARROW-13330: [Go][Parquet] Add the rest of the Encoding package #10716
Conversation
|
@emkornfield @sbinet Bump for visibility to get reviews |
|
Sorry busy week this week, will try to get to it EOW or sometime next week. |
|
@emkornfield bump |
|
sorry I have had less time then I would have liked recently for Arrow reviews, will try to get to this soon. |
| ) | ||
|
|
||
| func BenchmarkPlainEncodingBoolean(b *testing.B) { | ||
| for sz := MINSIZE; sz < MAXSIZE+1; sz *= 2 { |
There was a problem hiding this comment.
there isn't a built in construct in GO benchmarks for adjusting batch size?
There was a problem hiding this comment.
nope. b.N is the number of iterations to run under the benchmarking timer, so by doing this little loop it creates a separate benchmark for each of the batch sizes
| } | ||
|
|
||
| // EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush | ||
| // the buffer and return it yet, appending these encoded values. Returns the number |
There was a problem hiding this comment.
does it ever return less than the values provided in lvls? If so please document it (if not maybe still note that this is simply for the API consumer's convenience?)
There was a problem hiding this comment.
it should always return len(lvls), if it returns less that means it encountered an error/issue while encoding. I'll add that to the comment.
There was a problem hiding this comment.
so it is up to users to check that? should it propogate an error instead?
There was a problem hiding this comment.
currently this is an internal only package so it is not exposed for non-internal consumers to call this and the column writers check the return and propagate an error if it doesn't match. Alternately, I could modify the underlying encoders to have Put return an error instead of just a bool and then propagate an error. I believe currently it just returns true/false for success/failure out of convenience and I never got around to having it return a proper error.
I'll take a look at how big such a change would be.
There was a problem hiding this comment.
updated this change to add error propagation to all the necessary spots (and all the subsequent calls and dependencies) so that consumers no longer have to rely on checking the number of values returned but can see easily if an error was returned by the encoders.
…ck the number of values encoded.
|
@emkornfield bump. i've responded to and/or addressed all of the comments so far. 😄 |
|
|
||
| func TestDeltaByteArrayEncoding(t *testing.T) { | ||
| test := []parquet.ByteArray{[]byte("Hello"), []byte("World"), []byte("Foobar"), []byte("ABCDEF")} | ||
| expected := []byte{128, 1, 4, 4, 0, 0, 0, 0, 0, 0, 128, 1, 4, 4, 10, 0, 1, 0, 0, 0, 2, 0, 0, 0, 72, 101, 108, 108, 111, 87, 111, 114, 108, 100, 70, 111, 111, 98, 97, 114, 65, 66, 67, 68, 69, 70} |
There was a problem hiding this comment.
where do the expected values come from?
There was a problem hiding this comment.
The Delta Byte Array Encoding was implemented in another parquet library, so I stole the expected values from their unit tests and also did some manual confirmation to ensure they were the correct values to the best of my knowledge.
| Reset() | ||
| // Size returns the current number of unique values stored in the table | ||
| // including whether or not a null value has been passed in using GetOrInsertNull | ||
| Size() int |
There was a problem hiding this comment.
int is 32 bits here? does it pay to have errors returned for the insertion operations if they exceed that range?
There was a problem hiding this comment.
int is implementation defined, on 32 bit platforms int will be 32 bits, on 64 bit platforms it will be 64 bits.
In this memo table, I guess I assumed that it was unlikely that there'd ever be billions of elements in the table such that it was necessary or likely for a check to exceed the range of an int. Personally i'd prefer to not add the extra check inside of the insertion operation simply because it's a critical path that is likely to be inside of a tight loop so if possible, I'd prefer to avoid adding the check for whether the new size will exceed math.MaxInt but rather just document that the memotable has a limitation on the number of unique values it can hold being MaxInt. Thoughts?
| MemoTable | ||
| // ValuesSize returns the total number of bytes needed to copy all of the values | ||
| // from this table. | ||
| ValuesSize() int |
There was a problem hiding this comment.
this includes overhead for string length?
There was a problem hiding this comment.
No, it's just the raw bytes of the strings as they are stored like in an arrow array (since I back the binary memotable using a BinaryBuilder and just call DataLen on it). This is specifically used for copying the raw values as a single chunk of memory which is why the offsets are stored separately and copied out separately.
|
@emkornfield The performance difference is actually entirely based on the data and types (which is why I left both implementations in here). My current theory is that the custom hash table implementation (which I took from the C++ memo table implementation) is that it's simply a case of optimized handling of smaller values resulting is significantly fewer allocations. With go1.16.1 on my local laptop: The ones labeled xxh3 are my custom implementation and the go_map is the go builtin map based implementation, if you look closely at the results of the benchmark, in most cases, the xxh3 based implementation is fairly significantly faster, sometimes even twice as fast, with significantly fewer allocations per loop (for example, in the binary case with all unique values you can see the 2384 allocations in the go map based implementation vs the 53 in my custom implementation, having a ~37% performance improvement over the go-map based implementation. But if we look at some other cases, for example the TL;DR: All in all, in most cases, the custom implementation is faster but in some cases with lower cardinality of unique values (specifically int32 and binary strings) the implementation using go's map as the basis can be more performant. |
|
@emkornfield Just to tack on here, another interesting view is looking at a flame graph of the CPU profile for the
Looking at the flame graph you can see that a larger proportion of the CPU time for the builtin map-based implementation is spent in the map itself whether performing the hashes or accessing/growing/allocating vs adding the strings to the |
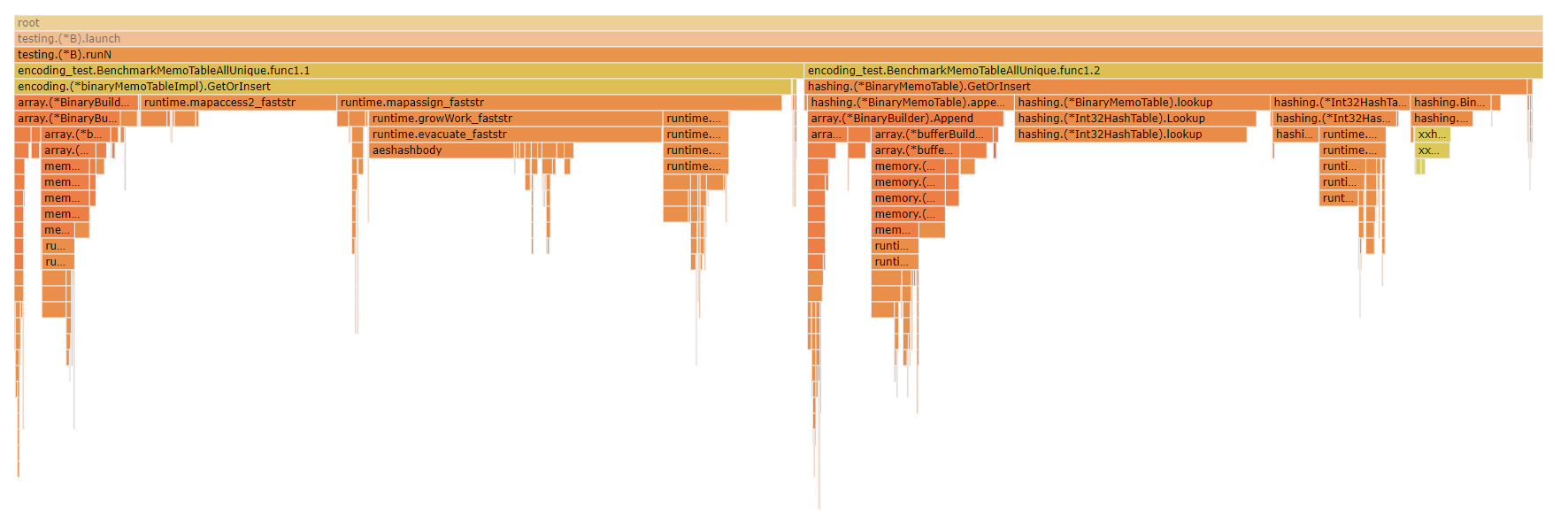
|
Just to chime in one last piece on this: while it's extremely interesting that a custom hash table is performing better than Go's builtin map in many cases, remember that we're still talking in absolute terms about differences of between 1ms and 0.1ms, so unless you're using it in a tight loop with a TON of entries/lookups, you're probably better off using Go's builtin map just because it's a simpler implementation and built-in rather than having to use a custom hash table implementation with external dependencies as it'll be more than sufficiently performant in most cases, but for this low level handling for dictionary encoding in parquet, the performance can become significant on the scale that this will be used, making it preferable to use the custom implementation. |
|
+1 merging. Thank you @zeroshade |
Here's the next chunk of code following the merging of #10716 Thankfully the metadata package is actually relatively small compared to everything else so far. @emkornfield @sbinet @nickpoorman for visibility Closes #10951 from zeroshade/parquet-metadata-package Authored-by: Matthew Topol <mtopol@factset.com> Signed-off-by: Matthew Topol <mtopol@factset.com>
Here's the next chunk of code following the merging of apache#10716 Thankfully the metadata package is actually relatively small compared to everything else so far. @emkornfield @sbinet @nickpoorman for visibility Closes apache#10951 from zeroshade/parquet-metadata-package Authored-by: Matthew Topol <mtopol@factset.com> Signed-off-by: Matthew Topol <mtopol@factset.com>
@emkornfield Thanks for merging the previous PR #10379
Here's the remaining files that we pulled out of that PR to shrink it down, including all the unit tests for the Encoding package.